Emilio Carrión
The DNA of software wasn't a concept. It was 24 files.
Three weeks ago I argued that code was going to become disposable, and what would matter is the DNA of the software. I locked myself in to check whether that idea was actually writable. What came out: 24 files, two regenerations for less than a euro each, a public repo, and a lot of clarity about what harness engineering still doesn't solve.
- 1When LLMs Generate Thousands of Tokens per Second, What Matters Won't Be the Code
- 2The DNA of software wasn't a concept. It was 24 files.
Three weeks ago I pulled out the crystal ball and tried to guess the future 🔮: when LLMs generate thousands of tokens per second, regenerating code will be cheaper than maintaining it (and faster even than reading it!). And then the question stops being "how do I write good code?" and becomes "what information lets me regenerate this system without losing its identity?". I called that information DNA.
That thesis had a problem. It was abstract. And as I admitted at the end of the post, abstract theses age badly when they don't get grounded. So I sat down for three weeks to check whether the DNA was actually writable or just sounded good.
It is. Twenty-four files.
Why a product, not a microservice
In the teams I work with, the conversation that comes up most these months isn't about how much code the agent generates. It's about how much we have to redo when what it produces doesn't fit what the system needs. And that doesn't get fixed by reviewing more carefully. It gets fixed in what we hand the agent before it starts.
The experiment in the previous post was with a microservice. Backend. And a microservice is generous with whoever regenerates it: tests, contracts, schemas. If the agent passes the tests, it's done the job.
A complete product is another story. Verification has to include things like "the menu communicates the type of cuisine in under ten seconds" or "the reservation button still works if the provider's iframe is down". That doesn't fit in OpenAPI. And here's what changes the math: most of the software we get paid to build lives in this group. Landings, microsites, internal dashboards, tools. If the DNA model only works for microservices, it touches a small slice of the business. If it works for product, it touches most of what we build.
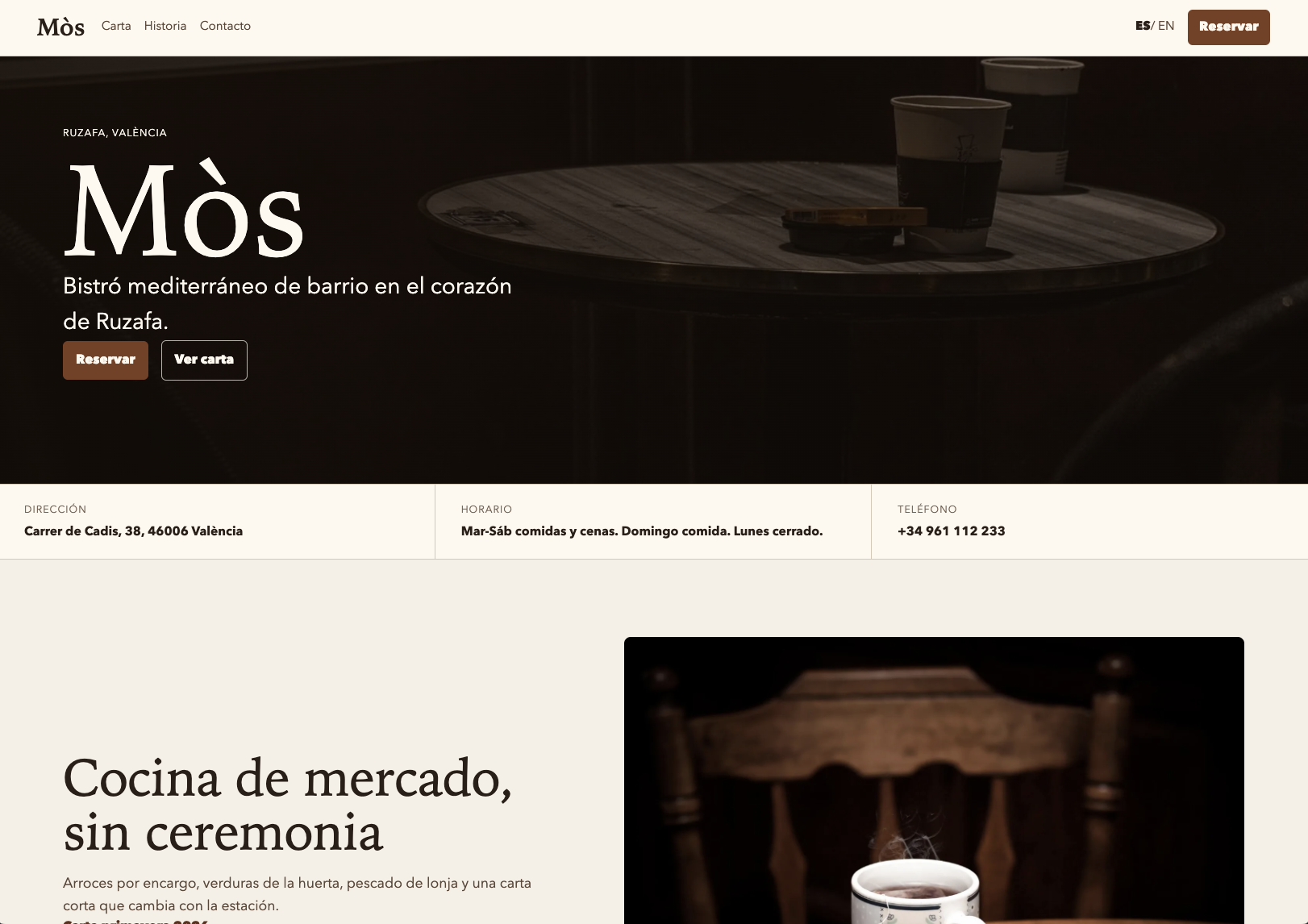
So I went for the hard case. I grabbed Astro, Tailwind, strict TypeScript, Codex CLI with GPT-5, and invented a Mediterranean restaurant in Ruzafa called Mòs. I started writing the DNA with the best structure I could come up with and hit the button. Two regenerations. The first was a bit of a disaster, but it failed in places that taught me what the DNA was missing. The second came out reasonable.
What's going to change the dynamics of the software economy: each full regeneration of Mòs costs less than a euro in tokens. It's not a hypothesis about 2028, it's what it cost last week with today's model. And that changes the math: if regenerating an entire product costs less than a coffee, code stops being the expensive part. The expensive part is not having written well what gets regenerated.
Here's what came out of run #2. None of the color, typography, or photos was specified in the DNA: the agent derived the entire aesthetic from prose.
The 24 files
If you don't want to look at the whole tree, the idea in one line: three folders, one for what the product does, one for what it's built with, one for the actual data. Plus two header files (one for the human who forks, one for the agent that regenerates). For the rest, this is what shows up when you open the blueprint:
restaurant-website/
README.md ← for the human who forks: what the blueprint produces
AGENTS.md ← for the agent: what to do, in what order, what to deliver
species/ ← what defines the genus, invariant
capabilities.md ← what it must be able to do (verifiable criteria)
quality.md ← how it does it well (performance, a11y, UX)
rationale.md ← why (short, deliberately underspecified)
contracts/ ← JSON Schemas that validate the instance
integrations/ ← contracts with third parties: maps, reservations, forms, photos
eval/ ← how regeneration is judged (must-have, judge prompts, lighthouse)
stack/ ← fixed technical decisions
technical.md ← framework, language, deploy
conventions.md ← repo layout, naming
components.md ← canonical component patterns
instance.example/ ← concrete product data (variable)
README.md ← step-by-step customization guide
brand.md ← the brand, in prose
config/ ← i18n, integrations, site
content/ ← menu, restaurant, story
overrides.md ← documented divergences from species
24 files in prose or YAML. I don't count the JSON Schemas because they're infrastructure for the machine, not DNA. If a contributor edits a schema, they're changing how the instance is validated, not changing what the product is.
The three layers from the previous post (what the system does, how it does it well, why it does it that way) all live inside species/, as capabilities.md, quality.md, and rationale.md. Those are the files I rewrote the most during the experiment. The rest is the infrastructure surrounding those three layers that lets an agent execute them without human supervision.
One decision that took me time: separating species/ from stack/. The species says what type of product it is (a restaurant with menu, reservations, map). The stack says with what tools it's built (Astro, strict TypeScript, static deploy). I separate them deliberately because the species should survive a stack change in two years. When a better framework shows up in 2028, I don't migrate code: I regenerate from the same species with a different stack.
instance.example/ is the variable piece. When someone forks the blueprint, they copy instance.example/ to instance/ and edit their concrete product there. The rest is reusable across forkers.
This isn't unusual, anyone who has documented a project has written similar files. The difference is that here the structure is designed so an agent reads it from start to finish and builds the product without coming back to ask you anything.
Enjoying what you read?
Join other engineers who receive reflections on career, leadership, and technology every week.
This newsletter is written in Spanish.
Where your DNA doesn't reach, the agent improvises
I'll tell it with two examples from run #1.
Example 1: the invisible navbar. It was translucent, floating as you scrolled. On dark backgrounds it was readable, but over light-background paragraphs it became invisible. White text on white background. It passed static accessibility (contrast ratios were measured against the background declared in CSS, not against what was actually behind it). It failed the human test in two seconds.
It wasn't an agent bug. It was a gap in the DNA. I hadn't written anywhere that "the legibility of persistent elements is measured against the worst possible backdrop they can overlap". And since it wasn't written, the agent decided for me. Reasonable, in fact: it did what 80% of the landings on the internet do. That rule, written once after run #1, now lives in species/quality.md under "Persistent UI legibility". Any blueprint that inherits it no longer trips on that stone.
Example 2: the map that wasn't a map. I had a capability that said "interactive map of the location with OpenStreetMap tiles". The agent delivered "a pretty text address with a link to Google Maps". It passed Lighthouse, it passed accessibility, it passed everything. But it had decided for me that a Leaflet (a standard library to display maps with zoom and drag, not a static image) was complicated, and downgraded the contract to its closest "reasonable" form, without warning.
Until I turned that capability into a strict MUST in species/capabilities.md with extra criteria ("interactive map means a rendered Leaflet, not a text address with an OSM link"), the agent was going to keep simplifying whatever it thought was excess.
The pattern is this: the agent takes invisible shortcuts every time your spec isn't explicit. And the shortcuts aren't neutral: each one introduces a degree of fragility that doesn't show up the day you deploy, but three months later, when someone has to touch the site and nobody remembers why something is the way it is. The DORA 2025 report is already starting to document that correlation in data.
What I didn't expect: these shortcuts are the most useful gift of the experiment, not the bug. Each one is a stone the next regenerations no longer trip on. The navbar rule, written once, serves every blueprint in the collection. The map criterion, same thing. Every gap discovered is compounding leverage.
The good thing is that the blueprint protocol captures them formally. The AGENTS.md requires the agent to deliver, alongside the site, a file instance/.generated/dna-gaps.md listing everything it had to decide without guidance. That file is the most valuable output of every regeneration. If it comes out short, that's an alarm: either there were no gaps (unlikely) or the agent papered over ambiguity without reporting it (the usual). When you read it, you know exactly which rules to write before the next one.
But the DNA shouldn't be exhaustive
I went into the experiment thinking the DNA had to be exhaustive, formal, closed. I came out thinking the opposite.
Mòs's brand.md was three pages of prose. No hex tokens, no predefined typography. One of the lines said: "Warm dimness. The light doesn't come from the ceiling, it comes from the tables: candles and a couple of low lamps with filament bulbs." Another: "We don't want tourists looking for paella on a terrace." The agent read that and derived a warm, dark palette, a typeface with weight, low-light photos, copy without tourist clichés. When I regenerated with run #2, the typography wavered between two reasonable options, but the character of the product stayed identical.
And that's why part of the DNA has to be deliberately underspecified, and the agent filling in with judgment is a feature, not a bug.
If you close the brand too tightly (hex tokens, predefined layouts, formal rules), the product loses personality and feels like a template. And the template feeling is, today, the number-one symptom of software made with badly used agents. Anyone notices. People close the tab.
If you leave it too open, the agent improvises toward the average of the corpus, which is the aesthetic of generic SaaS landing: gradient hero, glass card, "trusted by" with grayscale logos, three icons in a row with one-syllable words underneath. The default pattern of 2025.
The balance is writing prose with voice, but with a final test like "if X person in Y situation opens the page, what do they feel in ten seconds? If it's not this, the design is wrong". The agent uses that sentence as an anchor. And that solves the problem better than any system of closed tokens.
For me it changed where I had to put the care: I spent more time deciding what to leave underspecified in brand.md than it would have cost me to pick any hex token.
Why this is complementary to harness engineering
In February, Mitchell Hashimoto put a name on a related discipline: harness engineering. Designing the environment where the agent operates (tools, verification loops, AGENTS.md, sandboxes). In weeks it went from blog post to standard term: OpenAI picked it up after their experiment with Codex, Martin Fowler formalized it, Anthropic adopted it. It's good discipline and it's going to be good to have it on the team.
But it assumes an iterative process: an agent that works for days or weeks, an AGENTS.md that grows every time the agent makes a new mistake. Hashimoto adds a rule every time something fails. The OpenAI team wrote a million lines with Codex over five months with a harness that kept evolving.
That works very well for one class of tasks: codebases that grow, agents that live with the team every day, context that accumulates. It leaves out a different class: when you ask the agent to regenerate an entire product from scratch, in a single pass, without having been there before. There's no chance to iterate on the harness there. The quality of the product depends entirely on the spec the agent started from.
For an iterative task, a good AGENTS.md is enough. To build a whole product from scratch you need more: structuring the input in layers. And that's what I'm calling DNA. The quality of the result is decided in the initial spec, not in the agent's capacity.
The repo, as evidence
Today I'm opening github.com/EmilioCarrion/product-blueprints: four blueprints in v0.1, with their verifiable capabilities, their invariants, and their brand contract. The first public regeneration (Mòs) is hosted so you can browse it live: examples gallery.
Only the restaurant one is validated by two real regenerations. The other three are structurally correct but haven't been executed end to end. I'm saying it plainly because the difference between "framework" and "tested framework" matters, and because I've already seen enough AI Twitter to not want to fall on the wrong side of that line.
Why publish it now, if only one is validated? Two reasons. One, I need them myself: when a colleague asks me how to start the website for their side project, I'm going to hand them one of these. Two, the only way to discover the gaps I haven't seen alone is for more people to regenerate. Every gap is leverage for the next person who comes through.
Where I might be wrong
Two concrete places where my model can break, and I'm putting them on the table.
One, I don't know if the three DNA layers scale beyond small public products. An interactive dashboard with state, a mobile app with client-server coordination, an e-commerce with inventory and payments: there the layers may reorganize, or more may be needed. What I have works for four genres. That's not general proof.
Two, the concrete shortcuts I tell about (the invisible navbar, the degraded Leaflet) are contingent on this model and this moment. When GPT-5 becomes obsolete in six months, the examples are going to look quaint. The general pattern (the agent fills in where the DNA is silent) I think holds. But "I think" isn't "I prove".
I've been wrong before about how software engineering was going to evolve. It's possible I'm wrong now.
Question for you
If your work includes small public products (landings, microsites, event sites), fork one of the blueprints, write an instance/ for something of yours, and unleash an agent on it.
What helps me most is the dna-gaps.md the agent produces, not the site itself. That file is the list of places where the DNA stayed silent and the agent had to decide. Drop it as an issue or PR, or send it my way by email.
And if you work on a team where AI is being adopted seriously, the question worth asking is: are we measuring what the agent produces, or the quality of the DNA we produce with? If it's the first, we're heading in the direction the DORA data is already punishing.
The DNA only gets better when you actually try to write it.
This content was first sent to my newsletter
Every week I send exclusive reflections, resources, and deep analysis on software engineering, technical leadership, and career development. Don't miss the next one.
Join over 5,000 engineers who already receive exclusive content every week
Related articles
When LLMs Generate Thousands of Tokens per Second, What Matters Won't Be the Code
If regenerating is cheaper than maintaining, the rational strategy isn't to care for the code. It's to make it disposable by design and invest in what isn't disposable. The future of the engineer is writing DNA, not code.
Operating AI is easy. Directing it is the craft.
When everyone uses AI every day, mastering the tool stops being a differentiator. What matters is the stance you take toward it: operating or directing. And no agent puts its name on the line for you.
Discipline Doesn't Scale. Verification Needs Infrastructure.
Individual discipline as a quality system is a fragile design. Tests scaled because they became infrastructure. Verification needs to do the same.
